
突然想整一下 RL 于是就看上了 AlphaZero,围棋我也不会,训练也难,那就上一个五子棋版本
注意,这里展示的基本上是我跟着这些资料学习的流程,想要最终最完善的版本可以直接点目录跳转,有些代码已经优化改进,但是我还是把初稿放上来了
游戏环境实现
1 | # -*- coding: utf-8 -*- |
算法基本思路
传统的 MCTS 过程是这样的,给定一个棋面,MCTS 共进行 N 次模拟。主要的搜索阶段有 4 个:选择,扩展,仿真和回溯
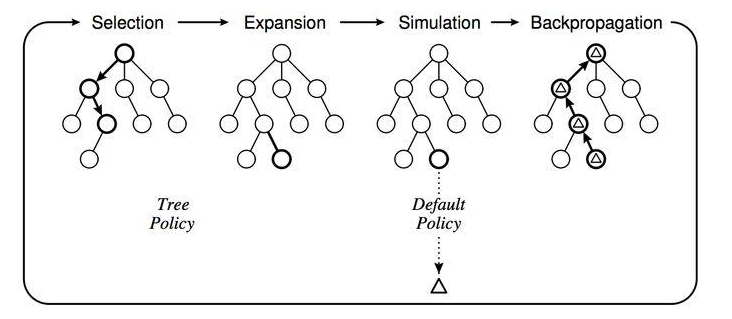
- 第一步是选择 (Selection),这一步会从根节点开始,每次都选一个“最值得搜索的子节点”,一般使用上限置信区间算法 (Upper Confidence Bound Apply to Tree, UCT) 选择分数最高的节点,直到来到一个“存在未扩展的子节点”的节点
- 第二步是扩展 (Expansion),在这个搜索到的“存在未扩展的子节点”之上,加上一个没有历史记录的子节点并初始化该子节点
- 第三步是仿真 (simulation),从上面这个没有试过的着法开始,用一个简单策略比如快速走子策略 (Rollout policy) 走到底,得到一个胜负结果。快速走子策略虽然不是很精确,但是速度较快,在这里具有优势。因为如果这个策略走得慢,结果虽然会更准确,但由于耗时多了,在单位时间内的模拟次数就少了,所以不一定会棋力更强,有可能会更弱。这也是为什么我们一般只模拟一次,因为如果模拟多次,虽然更准确,但更慢。
- 第四步是回溯 (backpropagation), 将我们最后得到的胜负结果回溯加到 MCTS 树结构上。注意除了之前的 MCTS 树要回溯外,新加入的节点也要加上一次胜负历史记录。[1]
而 AlphaZero 算法用一个神经网络代替了第三步的仿真过程,我个人的理解是神经网络拟合后的准确度比一次仿真高,而用时又比多次仿真少,所以能在不增加太多时间的情况下大幅提升准确度
基于 MCTS 的 player 实现
用 Python 实现传统 MCTS 搜索
MCTS 搜索代码逻辑都是差不多的(原理参照[2],这边仿照 @junxiaosong 的代码写了一份[3],要注意的关键点都在注释里了
1 | class TreeNode(object): |
AlphaZero 算法的 MCTS
直接继承上面的纯蒙特卡洛,重写 playout(一次完整的 MCTS 模拟,选择、扩展、仿真、回溯),其中用神经网络(policy_value_fn)代替仿真步骤。由于训练过程需要完整的决策概率,所以实现了 get_move_probs。
关于概率计算[1:1]
MCTS 搜索完毕后,模型就可以在 MCTS 的根节点 s 基于以下公式选择行棋的 MCTS 分支了:
τ 是用来控制探索的程度,τ 的取值介于 (0,1] 之间,当 τ越接近于 1 时,神经网络的采样越接近于 MCTS 的原始采样,当 τ 越接近于 0 时,神经网络的采样越接近于贪婪策略,即选择最大访问次数 N 所对应的动作。 因为在 τ 很小的情况下,直接计算访问次数 N 的 τ 次方根可能会导致数值异常,为了避免这种情况,在计算行动概率时,先将访问次数 N 加上一个非常小的数值(本项目是 1e-10),取自然对数后乘上 1/τ,再用一个简化的 softmax 函数将输出还原为概率,这和原始公式在数学上基本上是等效的。
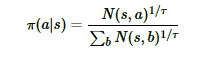
计算 softmax 时减去一个最大值是为了防止指数运算得到的结果过大,最终的结果仍是相同的。
1 | def softmax(x): |
基于两种不同的 MCTS 实现 player
1 | def random_rollout_policy_fn(board: Board): |
神经网络实现
这里我使用的网络与 @junxiaosong 并不相同,他使用的网络在 6x6 4 子连珠的情况下效果非常好,但是将棋盘扩大之后网络的拟合能力有些不足,效果没有那么好,所以我使用了残差层(ResidualBlock)。
具体的理论实现请参考[1:2]
1 | # -*- coding: utf-8 -*- |
训练流程
整体的思路是,先自我对弈收集数据,然后进行数据扩充(旋转,镜像),再通过梯度下降优化参数,循环进行
1 | # -*- coding: utf-8 -*- |
训练速度优化(C++多线程)
这部分才是本文的重点。在训练过程中会发现大部分的时间都花费在生成对局信息上了,这部分过程对算力的利用率很低,我一开始是想用 C++ 代替这部分(实际上我也试了,用 C++ 代替 MCTS 搜索之后,2000 次模拟用时从 8 秒多缩减到了 6 秒多,进一步分析后发现,模拟过程中大部分的时间其实在神经网络运算上),效果其实并不算好,想到可以多线程进行(最终实现是多线程同时生成对局 + 并行 MCTS,参考了 @hijkzzz [4])
其实我还写了一个 Python 多线程版本,但是写完之后想起来 Python 有一个 GIL 锁,会强制限制多线程到一个 CPU 核心,所以这样处理对性能没有帮助
以下是多线程高性能版本
值得一提的是,这些代码还存在一些问题
- 存在内存泄露,训练过程中内存越跑越大,具体什么原因没查出来,只看代码我没分析出来
- 是否能训练出优秀的模型存疑,因为到现在我并没有训练出一个在 11x11-5 的棋盘上有良好表现的模型
与 @hijkzzz 不同的是,我并没有使用 SWIG,而是使用了 pybind11
pybind11 环境配置
环境配置之所以单独拿出来说,是因为 Windows 环境下 pybind11 很容易出问题。
方式1 使用 Visual Studio
官方有详细教程 [5]
方式2 使用 CLion + CMake
CMakeList.txt
1 | cmake_minimum_required(VERSION 3.29) |
src 是我的 C++ 源码目录,其中 pybind11_DIR 通过指令
1 | python -m pybind11 --cmakedir |
获取,E:/Anaconda3/envs/paddle/Lib/site-packages/pybind11/include 这个路径是通过指令
1 | python -m pybind11 --includes |
获得(只要后半部分去掉 -I 就行,前半部分在 include_directories(${PYTHON_INCLUDE_PATH}) 已经导入)
有一个关键点是不要使用 find_package(Python3 COMPONENTS Interpreter Development),这样得到的是系统解释器,如果你使用虚拟环境,则会识别错误,应当在 CLion 中选用传递 Python 解释器。
工具链
构建配置
构建好之后把 .pyd 文件改名成包名直接放到工作目录下就好。
代码
https://github.com/syhanjin/Gomuku_Cpp_muti
未完待续(主要是我模型还没跑出来,这里只有原理